Month 4 - Not Enough Time
Due to the complexity of my project I was unable to complete all the required tasks of the project. By the time the pipeline was working from Image Gathering to Mesh Creation, I had less than a week to validate data and perform full run tests. This led to major flaws in my hypothesis that could not be accommodated with my remaining time.
Despite this, I was still able to present what I had and received valuable feedback and direction for the upcoming month. The Computer Science Master’s Committee were extremely gracious in providing me with positive feedback and I have a plan for month 5.
I will spend most of month 5 continuing to validate results and adjusting my hypothesis to account for the inherent error of the tools I am using. Specifically, phone GPS are only accurate to five meters, and Depth Anything 3 is only accurate to ± 20% of the actual distance from camera to pixel 92% of the time. This leaves a wide margin for error considering the objects I am trying to triangulate are anywhere from 10 to 100 meters away.
The biggest flaw in my original design is the resolution of the source imagery. Due to the distance of objects from many of the cameras, a very small amount of pixels are being provided to TripoSR for 3D generation. To counteract this, I would like to adjust the initial steps of my project to identify an object and then judge if the area of the bounding box is of a sufficient resolution for TripoSR. If the bounding box area is not large enough the user will be prompted to move closer or readjust their image.
Unfortunately, I will no longer be able to use Mapillary imagery as a source, but I will still be able to create a cheaper alternative to generating 3D meshes of individual objects in an area.
Month 3 - Object Matching Implementation
Month three of working on LA3DG was all about object matching. This involved extracting monocular depth estimates from the downloaded imagery and its associated metadata. To do this I used Depth Anything V3. Depth Anything provides a depth map of a resized version of the original image. Using this depth map, I was able to resize and overlay object masks to find the bottom-closest pixel of the object to the camera. This allows me to estimate the distance of the object from the camera, as well as the object’s angle from the center of the image. By combining the object’s angle with the heading of the camera, I can then estimate the coordinates of the bottom-closest pixel. If two objects, from separate images are then found to be within two meters of one another, they are potentially the matching.
Over spring break I plan to train and implement a feature matching AI module to further validate the possible matches. I look forward to this aspect of the project because my main area of focus is AI. I feel that I can setup individual AI models and chain them together, but I have little experience actually preparing data and training AI to perform specialized tasks. This is something I am excited to learn and look forward to next month and over spring break.
Month 2 - Image Gathering, Filtering, and Cleaning
By: Johnathan Coots
For month 2 I focused on the gathering of images via Mapillary API, filtering out indoor images via Places365, and inpainting dynamic objects via RF-DETR image segmentation and LaMa inpainting.
Using the Mapillary API was a little difficult for me due to my inexperience with web sessions, but their documentation made the requesting understandable. Essentially, you ask for all the image information in a box that is dictated by the minimum and maximum latitudes and longitudes of the desired area. That returns a list of metadata that includes the associated image IDs. You then send a follow-up request to download the images as JSON objects via their image ID. The only caveats to this process are the limit to area size (0.01 square-geographic-degrees, which is huge) and the maximum image count of 2000 images. I did run into some confusion with the wording about pagination of responses regarding the 2000 image limit. Initially I thought the types of requests I would be sending would require me to follow up with a “Next Page” response, but after some careful reading of the documentation I believe this is only necessary if a sub-user is accessing the API via my access token.
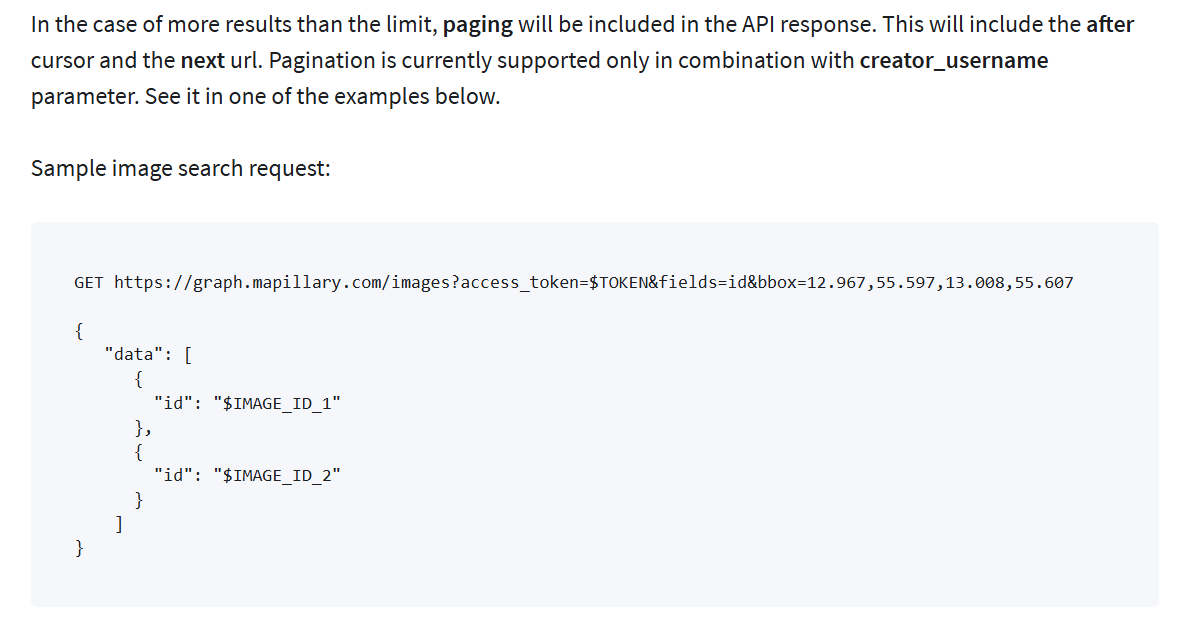
Mapillary API documentation.
The Places365 implementation went smoothly due to previous experience with the repository, and I am successfully filtering indoor images from the data set.
I am currently running into some difficulties with the LaMa inpainting. During the implementation of the LaMa repository, I ran into some package conflicts. To try and avoid this I tried using an alternative repository, but the results have been subpar. A potential issue is that I am using a RF-DETR segmentation model when I previously used an Ultralytics one, but I do not believe this is the issue so far. I have inspected the image masks RF-DETR model created and they seem accurate. Instead, I will return to the original LaMa model I planned on using and try to resolve the package conflicts.

Current inpainting implemented in LA3DG.

Inpainting achieved in a previous project.
Once the inpainting has been improved I plan on implementing the MiDaS depth estimation. This will lead to the object matching and triangulation portions of the pipeline. My major goals for month 3 are to implement the object matching, triangulation, and NeRF portions of the pipeline so that I can spend month 4 focusing on paper work a refinement of the application.

MiDaS visualization.
Month 1 - The Proposal
I recently performed my proposal presentation for LA3DG.
The major feedback I received is:
Concern towards the complexity of the project.
The importance of qualitative validation alongside quantitative findings.
The need for a refined hypothesis.
I too am concerned about the complexity of the project. I am fortunate in that I am continuing from previous work in the degree, so the automated image collection, filtering, and inpainting portions are essentially completed. There is also a working UI that only needs some adjustments to ease the output folder selection process. These UI implementations have been previously performed in another class when I created a basic data visualization software. Although, the scope of the work is huge, I do feel ready.
I did not originally recognize areas in which 3rd party validation would be beneficial - and required - but I appreciated the feedback. I initially thought my results would require qualitative feed back; but upon further research, I found that the team responsible for previous NeRF research utilized quantitative measures to grade their 3D models. After, studying PSNR, SSIM, and LPIPS, I completely dropped the idea of utilizing qualitative findings at all. However, it is unwise for me to determine if images contain the same object because there is the perceivable risk of data manipulation - a highly unethical practice that I do not want to be associated with.
Lastly, I included in my hypothesis various goals that were deemed unnecessary. I originally included these goals to force myself to monitor the various AI modules incorporated into LA3DG. However, they did not directly relate to the goals of LA3DG and caused committee members to recommend a refinement of my hypothesis. Luckily, I was able to determine which portions of the hypothesis to exclude on the spot and adequately supported the rest. I believe this led to the overall acceptance of my proposal and I am thankful to the committee for their positive response.
Month 1 - Paperwork, paperwork, paperwork!
Month 1 of the project mostly consisted of creating the necessary documentation to proceed with the research into Large Area 3D Generation. Although the research is primarily academic, a noticeable portion of assignments acknowledged the potential commercialization of the project.
In order to meet the needs of potential consumers, reviews of similar products were taken into consideration. Both positive reviews - such as those focused on inspirational aspects of real-world 3D recreations - and the negative - a lack of intuitive controls and bloat features.
Similar to projects found in the industry, a high level design document was developed. This document has been a boon when completing the downstream assignments because it acts as a road map for the project as a whole.
To emphasize the importance of societal benefits, a project requirements document and SWOT analysis were created and IRB training was refreshed. To add to this, IRB documentation was also created to ensure any study participants are adequately protected.
In order to procure sufficient training and validation data for a potential object matching AI module, a study was designed to allow participants to determine if multiple images contained the same object. The study would task participants to analyze pairs of images and answer if both images contained the same object. For example, the first image is of a car from the front and the second image is of a car from the left. The car - in both images - is wrapped in a box labeled “car” as well. In this case the participant would answer “yes”. If the labels do not match or the objects are clearly different - such as two different types of trees, or a tree and a house - then the participant should answer “no”.
While AI training data will help the object matching module of the project, I value the participants’ privacy more so. As such, all of the yes and no answers will be collected anonymously. This ensures the only personally identifiable information collected is a copy of the consent form.
What is Large Area 3D Generation?
Large Area 3D Generation (LA3DG) is an automated system that utilizes open-source imagery of real-world areas to produce 3D meshes that recreate said areas. By entering geographic coordinates and area dimensions, open-source imagery will be gathered and prepared for the generation of NeRF models that are then converted to 3D meshes and a cohesive scene.